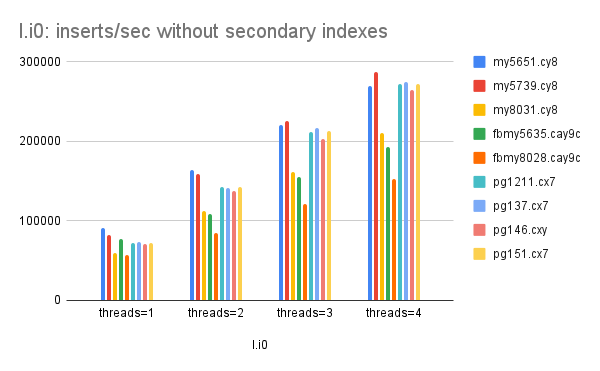
I used the insert benchmark to compare ARM and x86 servers on AWS. For ARM I used c7g and for x86 I used c6i. The goal was to compare ARM vs x86 on similar hardware (OS, vcpu, RAM and EBS setups were the same).
While I am not trying to start a benchmarketing battle for c7g vs c6i or Postgres vs MySQL, I suppose that might happen. My goal in doing comparisons like this is to find things that can be improved. Also, in-memory workloads aren't the target use case for MyRocks. It doesn't do great on them. It does do great on write and space efficiency, but those don't matter here. Were this an IO-bound benchmark the MyRocks results would look much better in comparisons.
tl;dr
- Performance for x86 (c6i) and Arm (c7g) were mostly similar for medium and high concurrency while x86 was faster at 1 client thread. But there were large differences on the high concurrency tests for Postgres - in a few cases Arm did much better, in a few x86 did much better.
- Some performance problems, like the Postgres QPS drop off at high concurrency, might be resolved by using better compiler flags in the build. Figuring that out is future work.
- Hyperthreading on Intel rarely improved performance and frequently hurt it
- For inserts in PK order without secondary indexes
- Perf at low concurrency is similar for MyRocks and InnoDB and slightly better for Postgres
- MyRocks does the worst as concurrency & instance size grow
- For inserts in PK order with 3 secondary indexes
- Perf at low concurrency is similar
- MyRocks does the worst and Postgres the best as concurrency & instance size grow
- For range queries with background writes
- InnoDB is slightly faster than MyRocks, Postgres is much faster than both
- Postgres does the best as concurrency & instance size grow with one exception. On the 16xlarge instance Postgres QPS is better with 22 threads than with 44 on Arm (c7g), but on x86 (c6i) the QPS is better with 44 threads as expected.
- The usage of prepared statements improves Postgres QPS by ~1.25X for q100, q500 and q1000 on 16xl.22t. I have to make prepared statements work for MySQL, or at least get good results,
Compiling
The benchmark was repeated for Postgres 15.1, MySQL 8.0.31 with InnoDB and FB MySQL 8.0.28 with MyRocks. All were compiled from source with gcc (gcc 11.3.0 on Ubuntu 22.04) and I didn't go out of my way to change the compiler flags.
For the builds on ARM:
- MySQL uses -march=armv8-a+crc for all (or most) files
- MyRocks uses -march=armv8-a+crc+crypto for all (or most) files
- Postgres uses -march=armv8-a+crc for a few files -- the ones related for crc32c
- MySQL doesn't use -march, -mtune or -mcpu. It does use -O2.
- MyRocks uses -march=native and -O2.
- Postgres doesn't use -march, -mtune or -mcpu. It does use -O2.
- Arm -> use -mcpu=native for clang and gcc. Perhaps -mcpu=neoverse-512tvb is better, but -mcpu=native is easier to remember.
- x86 -> use -march=native for clang and gcc
Benchmark
An overview of the insert benchmark is here and an update is here. I used a CPU-bound workload, the database fits in the DBMS cache so there were no reads from storage but many writes.
The benchmark was repeated for Postgres 15.1, MySQL 8.0.31 with InnoDB and FB MySQL 8.0.28 with MyRocks.
The insert benchmark was run with 6 steps:
- l.i0 - insert X rows without secondary indexes
- l.x - create 3 secondary indexes. I ignore performance for this step. Some of the tested DBMS do a parallel index create that I haven't tried to tune.
- l.i1 - insert Y rows with 3 secondary indexes in place
- q100 - queries with 100 inserts/s/thread in the background, runs for 1 hour
- q500 - queries with 500 inserts/s/thread in the background, runs for 1 hour
- q1000 - queries with 1000 inserts/s/thread in the background, runs for 1 hour
- 2xlarge - X=10M, Y=10M, 1 thread
- 4xlarge - X=25M, Y=25M, 4 & 8 threads
- 8xlarge - X=75M, Y=25M, 8 & 16 threads
- 16xlarge - X=150M, Y=50M, 22 & 44 threads
Servers
All servers use Ubuntu 22.04 with database storage on EBS (io2). The EBS setups for each vcpu size were the same between c7g and c6i except for the 16xlarge case where c7g gets more IOPs (I made a mistake there).
For ARM I used:
- c7g.2xlarge
- 8 vcpu, 8 CPU, 16G RAM, EBS (256G, io2, 10k IOPs)
- c7g.4xlarge
- 16 vcpu, 16 CPU, 32G RAM, EBS (1T, io2, 32k IOPs)
- c7g.8xlarge
- 32 vcpu, 32 CPU, 64G RAM, EBS (2T, 49k IOPs)
- c7g.16xlarge
- 64 vcpu, 64 CPU, 128G RAM, EBS (5T, 100k IOPs)
For x86 I used:
- c6i.2xlarge
- 8 vcpu, 4 CPU, 16G RAM, EBS (256G, io2, 10k IOPs), hyperthread disabled
- c6i.4xlarge
- 16 vcpu, 8 CPU, 32G RAM, EBS (1T, io2, 32k IOPs), hyperthread disabled
- c6i.8xlarge
- 32 vcpu, 16 CPU, 64G RAM, EBS (2T, io2, 49k IOPs), hyperthread disabled
- c6i.16xlarge
- 64 vcpu, 32 CPU, 128G RAM, EBS (5T, io2, 64k IOPs), hyperthread disabled
- 2xlarge - MyRocks, MySQL/InnoDB, Postgres
- 4xlarge - MyRocks, MySQL/InnoDB, Postgres
- 8xlarge - MyRocks, MySQL/InnoDB, Postgres
- 16xlarge - MyRocks, MySQL/InnoDB, Postgres
I disable hyperthreading for x86 as that tends to hurt benchmark QPS and/or QoS thus /proc/cpuinfo shows that the ARM servers have 2X the CPUs. For the 16xlarge instance this (HT doesn't help perf) is mostly true for most of the DBMS X benchmark steps at 22 threads and somewhat true at 44 threads:
Results
Performance summaries are here. A brief guide to reading them is here:
- 2xlarge, 20M rows, 1 thread - for c6i and for c7g
- 4xlarge, 50M rows, 4 threads - for c6i and for c7g
- 4xlarge, 50M rows, 8 threads - for c6i and for c7g
- 8xlarge, 100M rows, 8 threads - for c6i and for c7g
- 8xlarge, 100M rows, 16 threads - for c6i and for c7g
- 16xlarge, 500M rows, 22 threads - for c6i and for c7g
- 16xlarge, 500M rows, 44 threads - for c6i and for c7g
- fbmy8028.c6i and fbmy8028.c7g are for MyRocks on c6i and c7g
- my8031.c6i and my8031.c7g are for InnoDB on c6i and c7g
- pg151.c6i and pg151.c7g are for Postgres on c6i and c7g
- 2xl.1t is 2xlarge with 1 thread (client)
- 4xl.4t is 4xlarge with 4 threads (clients)
- 4xl.8t is 4xlarge with 8 threads (clients)
- 8xl.8t is 8xlarge with 8 threads (clients)
- 8xl.16t is 8xlarge with 16 threads (clients)
- 16xl.22t is 16xlarge with 22 threads (clients)
- 16xl.44t is 16xlarge with 44 threads (clients)
- Results are similar between Arm and x86
- Results are similar between DBMS at low concurrency but as server size and concurrency increases Postgres does the best and MyRocks does the worst.

- Results are similar between Arm and x86 but Arm does better for Postgres at high concurrency
- Results are similar between DBMS at low concurrency but as server size and concurrency increases Postgres does the best and MyRocks does the worst.

- Results are similar between Arm and x86 although results for Postgres at high concurrency are odd, especially for 16xl.44t (16xlarge, 44 threads) where QPS for c7g is bad on Arm but good on x86. Perhaps one issue is the compiler optimization flags mentioned above.
- Postgres gets much more QPS than MySQL. One reason is that the benchmark uses prepared statements for Postgres but I have yet to make that work for MySQL. The usage of prepared statements improves Postgres QPS by ~1.25X for q100, q500 and q1000 on 16xl.22t.



- Results were better for x86 than for Arm.
- For l.i0 the CPU usecs/insert (cpupq) is 10 for Postgres, 11 for InnoDB and 12 for MyRocks. So Postgres has the least CPU overhead. For cpupq see here for x86 and for Arm.
- For l.i1 the CPU usecs/insert (cpupq) is 24 for Postgres, 27 for InnoDB and 38 for MyRocks. Again, Postgres has the least CPU overhead. For cpupq see here for x86 and for Arm.
- For the range query with background insert tests Postgres QPS is ~2X the QPS for MyRocks and InnoDB because the CPU usecs/query (cpupq) is at least 2X larger for MySQL than for Postgres. For cpupq see here for x86 and for Arm. For the q100 benchmark step the CPU usecs/query is 53 for Postgres, 109 for InnoDB and 140 for MyRocks. One issue is that I am able to use prepared statements for Postgres but have yet to make them work, or get good results with them, for MySQL.
- Arm did better than x86 for the load benchmark steps (l.i0, l.i1), but for the range query benchmark steps (q100, q500, q1000) the results for Arm and x86 were similar. While x86 did better than Arm for the 8xl.8t (8xlarge, 8 thread) test. The issue might be that CPU was oversubscribed with x86 for 8xl.16t and the load steps require CPU for background threads to persist the database state. The 8xl server has 32 cores for Arm and 16 for x86 because hyperthreading was disabled. The 8xl.16t benchmark uses 16 threads for inserts and then InnoDB needs some and MyRocks needs more background threads.
- For l.i0 and x86 the CPU usecs/insert is 11 for Postgres, 14 for InnoDB and 19 for MyRocks (see cpupq here). For Arm it is 13 for Postgres, 16 for InnoDB and 23 for MyRocks (see cpupq here).
- For l.i1 and x86 the CPU usecs/insert is 27 for Postgres, 34 for InnoDB and 40 for MyRocks (see cpupq here). For Arm it is 31 for Postgres, 40 for InnoDB and 45 for MyRocks (see cpupq here). The context switch rate (which predicts mutex contention) is smallest for Postgres - see cspq (context switches/query).
- For range query perf I focus on q100 but q500 and q1000 are similar. For x86 the CPU usecs/insert is 54 for Postgres, 127 for InnoDB and 164 for MyRocks (see cpupq here). For Arm it is 58 for Postgres, 152 for InnoDB and 203 for MyRocks (see cpupq here). The context switch rates are similar for Postgres and MySQL -- about 1.9/query.
- Results are similar between Arm and x86 for the load benchmark steps (l.i0, l.i1). For the range query steps (q100, q500, q1000) the QPS for Arm and x86 is similar for MySQL but for Postgres the Arm results are much better than x86.
- For l.i0 Postgres has the best insert rates and MyRocks has the worst. For x86 the CPU usecs/insert is 12 for Postgres, 15 for InnoDB and 23 for MyRocks (see cpupq here) and for Arm it is 13 for Postgres, 17 for InnoDB and 25 for MyRocks (see cpupq here). The context switch rate/insert is also lower for Postgres -- see the cspq column (context switches/query).
- For l.i1 Postgres has the best insert rates and MyRocks has the worst. The CPU usecs/insert is 30 for Postgres, 35 for InnoDB and 45 for MyRocks (see cpupq here) and for Arm it is 30 for Postgres, 40 for InnoDB and 53 for MyRocks (see cpupq here).
- For the range query benchmark steps (q100, q500, q1000) InnoDB is slightly faster than MyRocks and Postgres is much faster than both. The QPS for Postgres on Arm is much better than on x86. For q100 and x86 the CPU usecs/query is 80 for Postgres, 144 for InnoDB and 175 for MyRocks (see cpupq here). For Arm it is 54 for Postgres, 153 for InnoDB and 196 for MyRocks (see cpupq here). The ratio (cpupq for InnoDB / cpupq for Postgres) is 1.8 on x86 and 2.8 on Arm. The context switch rates are similar between Postgres and MySQL.
- Results are similar between Arm and x86 for l.i0 but have more variance for l.i1 (Postgres and InnoDB did better with Arm, MyRocks did better with x86). For the range query steps (q100, q500, q1000) the QPS for Postgres was much better on x86 than on Arm while the QPS for InnoDB and MyRocks was similar between x86 and Arm.
- For l.i0 the CPU usecs/insert was 12 for Postgres, 15 for InnoDB and 24 for MyRocks on x86 (see cpupq here). For Arm it was 12 for Postgres, 17 for InnoDB and 33 for MyRocks (see cpupq here). Context switch rates were best for Postgres and much worse for MyRocks on both x86 and Arm (see the cspq value).
- For l.i1 the CPU usecs/insert was 30 for Postgres, 35 for InnoDB and 48 for MyRock on x86 (see cpupq here). For Arm it was 31 for Postgres, 41 for InnoDB and 58 for MyRocks (see cpupq here). The insert rate for Postgres was ~1.15X better on Arm than x86 and that might be explained by a lower context switch rate (cspq) on Arm (0.457 on Arm, 0.525 on x86). As mentioned elsewhere, this might be a result of an oversubscribed CPU on the x86 benchmarks.
- For the range query benchmark steps (q100, q500, q1000) the CPU usecs/query is 58 for Postgres, 136 for InnoDB and 171 for MyRocks on x86 (see cpupq here). For Arm it was 119 for Postgres, 218 for InnoDB and 258 for MyRocks (see cpupq here). The context switch rates (cspq) for all DBMs were ~1.9/query on x86 and ~3.9/query on Arm. The bad results for Postgres on Arm might be explained by using ~1.3X CPU/query than on x86.