I ran experiments with performance regression tests on AWS servers to measure throughput variance across multiple runs of the benchmarks. I search for a setup with less QPS variance to reduce false positives during performance regression tests.
The goals were to determine:
- Which instances have less variance
- Whether there is less variance with hyperthreading enabled or disabled
- Whether there is less variance with EBS (io2) or local SSD
The results were good for most of the instance types that I tried. By good I mean that the max coefficient of variance (stddev/mean) of the QPS for all benchmark steps of a given (server type, number of client threads) pair is less than 3%. Scroll down to the Which to choose section to see the list.
Servers
My focus was on m5d because m5d.2xl.ht1.nvme is the current setup used for automated tests. In the names I use below ht0 means hyperthreading disabled and ht1 means hyperthreading enabled.
The servers that I tested are:
- m5.2xl.ht0, m5.2xl.ht1
- m5.2xlarge, 8 vcpu, 32G RAM, EBS (io2, 1T, 32K IOPs), hyperthread disabled/enabled
- m5d.2xl.ht0.nvme, m5d.2xl.ht1.nvme
- m5d.2xlarge, 8 vcpu, 32G RAM, local NVMe SSD (300G), hyperthread disabled/enabled
- m5d.2xl.ht0.io2, m5d.2xl.ht1.io2
- m5d.2xlarge, 8 vcpu, 32G RAM, EBS (io2, 1T, 32K IOPs), hyperthread disabled/enabled
- m5d.4xl.ht0.nvme, m5d.4xl.ht1.nvme
- m5d.4xlarge, 16 vcpu, 64G RAM, local NVMe SSD (300G), hyperthread disabled/enabled
- m5d.4xl.ht0.io2, m5d.4xl.ht1.io2
- m5d.4xlarge, 16 vcpu, 64G RAM, EBS(io2, 1T, 64K IOPs), hyperthread disabled/enabled
- c6i.2xl.ht1
- c6i.2xlarge, 8 vcpu, 16G RAM, EBS(io2, 1T, 32K IOPs), hyperthread enabled
- c6i.4xl.ht0, c6i.4xl.ht1
- c6i.4xlarge, 16 vcpu, 32G RAM, EBS(io2, 1T, 64K IOPs), hyperthread disabled/enabled
- c6i.8xl.ht0, c6i.8xl.ht1
- c6i.8xlarge, 32 vcpu, 64G RAM, EBS(io2, 2T, 64K IOPs), hyperthread disabled/enabled
- c6i.12xl.ht0, c6i.12xl.ht1
- c6i.12xlarge, 48 vcpu, 96G RAM, EBS(io2, 2T, 64K IOPs), hyperthread disabled/enabled
Benchmark
An overview of how I run RocksDB benchmarks is here. The benchmark was run 3 times per server type and I focus on QPS using standard deviation and coefficient of variance (stddev / mean).
I used a fork of the RocksDB benchmark scripts. My fork is here and then I applied another diff to disable one of the benchmark steps to save time. My helper scripts make it easy for me to run the benchmarks with reasonable configuration options. The important things the helper scripts do are:
- Configure the shape of the LSM tree so there will be enough levels even with a small database
- Set max_background_jobs as a function of the number of CPU cores
- Set the RocksDB block cache size as a function of the amount of RAM
The benchmark was started using x3.sh like this this where $nt is the number of client threads, $cfg is the RocksDB configuration, $num_mem is the number of KV pairs for a cached workload and $num_io is the number of KV pairs for an IO-bound workload:
CI_TESTS_ONLY=true bash x3.sh $nt no 1800 $cfg $num_mem $num_io byrx iobuf
Rather than name the config I describe the values for max_background_jobs (mbj) and the block cache size (bc). The values per server type for nt, mbj, bc, num_mem, num_io were:
- m5.2xl.ht0, m5.2xl.ht1
- mbj=4, bc=24g, num_mem=40M, num_io=1B, nt=1,4
- m5d.2xl.ht0.nvme, m5d.2xl.ht1.nvme
- mbj=4, bc=24g, num_mem=40M, num_io=750M, nt=1,2,4
- m5d.2xl.ht0.io2, m5d.2xl.ht1.io2
- mbj=4, bc=24g, num_mem=40M, num_io=750M, nt=1,2,4
- m5d.4xl.ht0.nvme, m5d.4xl.ht1.nvme
- mbj=8, bc=52g, num_mem=40M, num_io=750M, nt=1,4,8
- m5d.4xl.ht0.io2, m5d.4xl.ht1.io2
- mbj=8, bc=52g, num_mem=40M, num_io=750M, nt=1,4,8
- c6i.2xl.ht1
- mbj=4, bc=12G, num_mem=40M, num_io=1B, nt=4
- With num_mem=40M the database is slightly larger than memory. I should have used 20M.
- c6i.4xl.ht0
- mbj=4, bc=24G, num_mem=40M, num_io=1B, nt=4
- c6i.4xl.ht1
- mbj=8, bc=24G, num_mem=40M, num_io=2B, nt=8
- c6i.8xl.ht0
- mbj=8, bc=52G, num_mem=40M, num_io=2B, nt=8
- c6i.8xl.ht1
- mbj=8, bc=52G, num_mem=40M, num_io=2B, nt=16
- c6i.12xl.ht0
- mbj=8, bc=80G, num_mem=40M, num_io=2B, nt=16
- c6i.12xl.ht1
- mbj=8, bc=80G, num_mem=40M, num_io=3B, nt=24
Graphs for a cached workload
This section has results for a cached workload, described as byrx earlier in this post. The benchmark steps are described here. The graphs show the coefficient of variance (stddev/mean) of the QPS for these benchmark steps: fillseq, readrandom, fwdrangewhilewriting, readwhilewriting and overwrite. Note that to save space the graphs use fwdrangeww and readww in place of fwdrangewhilewriting and readwhilewriting. For reasons I have yet to fully explain the range query tests (fwdrangewhilewriting here) tend to have more QPS variance regardless of hardware.
The graph for 1 client thread is here. The worst variance occurs for m5.2xl.ht0, m5.2xl.ht1, m5d.2xl.ht0.io2 and m5d.2xl.ht1.io2.
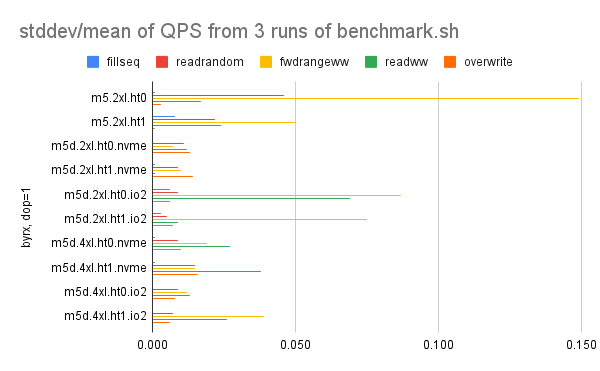
The graph for 2 client threads is here. The worst variance occurs for m5d.2xl.ht1.nvme and m5d.2xl.ht0.io2.

The graph for 4 client threads is here. The worst variance occurs for m5d.2xl.ht?.nvme, m5d.2xl.ht0.io2, m5d.4xl.ht0.nvme, m5d.4xl.ht0.io2 and c6i.2xl.ht1. I wrote above that the database didn't fit in the DBMS cache for c6i.2xl.ht1 which might explain why it is an outlier.

The graph for 8 client threads is here. The worst results occur for m5d.4xl.ht?.nvme and m5d.4xl.ht0.io2.


Graphs for an IO-bound workload
This section has results for an IO-bound workload, described as iobuf earlier in this post. The benchmark steps are described here. The graphs show the coefficient of variance (stddev/mean) of the QPS for these benchmark steps: fillseq, readrandom, fwdrangewhilewriting, readwhilewriting and overwrite. Note that to save space the graphs use fwdrangeww and readww in place of fwdrangewhilewriting and readwhilewriting.
The graph for 1 client thread is here. The worst results occur for m5d.2xl.ht0.nvme, m5d.2xl.ht0.io2 and m5d.4xl.*.

The graph for 2 client threads is here. The worst results occur for m5d.2xl.ht0.nvme.

The graph for 4 client threads is here. The worst results occur for m5.2xl.ht1, m5d.2xl.*.nvme, m5d.4xl.ht0.io2 and c6i.2xl.ht1.

The graph for 8 client threads is here. The worst results occur for m5d.4xl.ht0.io2 and c6i.4xl.ht1.

The graph for 16 client threads is here. The worst results occur for c6i.8xlarge.ht1.

Which to choose?
Which setup (server type + number of client threads) should be used to minimize variance? The tables below list the maximum and average coefficient of variance from all tests for a given setup where dop=X is the number of client threads. I will wave my hands and claim a good result is a max coefficient of variance that is <= .03 (.03 = 3%).
These setups have good results for both cached (byrx) and IO-bound (iobuf) workloads:
- m5d.2xl.ht0.nvme - dop=1,2
- m5d.2xl.ht1.nvme - dop=1
- m5d.2xl.ht1.io2 - dop=2,4
- m5d.4xl.ht0.nvme - dop=1,4,8
- m5d.4xl.ht1.nvme - dop=4,8
- m5d.4xl.ht0.io2 - dop=1,4,8
- m5d.4xl.ht1.io2 - dop=4,8
- c6i.4xl.ht0 - dop=4
- c6i.4xl.ht1 - dop=8
- c6i.8xl.ht0 - dop=8
- c6i.8xl.ht1 - dop=16
- c6i.12xl.ht0 - dop=16
These are results for iobuf (database is larger than memory).
Performance summaries
In the linked URLs below: byrx means cached by RocksDB and iobuf means IO-bound with buffered IO. The links are to the performance summaries generated by the benchmark scripts.
Results for dop=1
- m5.2xlarge
- m5d.2xlarge with nvme
- m5d.2xlarge with io2
- m5d.4xlarge with nvme
- m5d.4xlarge with io2
- m5.2xlarge
- m5d.2xlarge with nvme
- m5d.2xlarge with io2
- m5d.4xlarge with nvme
- m5d.4xlarge with io2
- c6i.2xlarge
- c6i.4xlarge
- m5d.4xlarge with nvme
- m5d.4xlarge with io2
- c6i.4xlarge
- c6i.8xlarge
https://github.com/facebook/rocksdb/issues/11017
ReplyDelete