The
log structured merge tree (LSM) is an interesting algorithm. It was designed for disks yet has been shown to be effective on SSD. Not all algorithms grow better with age. A long time ago I met one of the LSM co-inventors,
Patrick O'Neil, at the first job I had after graduate school. He was advising my team on
bitmap indexes. He did early and interesting work on both topics. I went on to maintain bitmap index code in the Oracle RDBMS for a few years. Patrick O'Neil made my career more interesting.
Performance evaluations are hard. It took me a long time to get expertise in InnoDB, then I repeated that for
RocksDB. Along the way I made many mistakes. Advice on doing benchmarks for RocksDB is
here and
here.
tl;dr - the MyRocks advantage is better compression and less write-amplification
The MyRocks Advantage
There are many benefits of the MyRocks LSM relative to a B-Tree. If you want to try MyRocks the source is
on github, there is
a wiki with notes on
building,
my.cnf and more details on the
MyRocks advantage. Track down Yoshinori at the
MyRocks tutorial at Percona Live or his
talk at FOSDEM to learn more. The advantages include:
- better compression - on real and synthetic workloads we measure 2X better compression with MyRocks compared to compressed InnoDB. A B-Tree wastes space when pages fragment. An LSM doesn't fragment. While an LSM can waste space from old versions of rows, with leveled compaction the overhead is ~10% of the database size compared to between 33% and 50% for a fragmented B-Tree and I have confirmed such fragmentation in production. MyRocks also uses less space for per-row metadata than InnoDB. Finally, InnoDB disk pages have a fixed size and more space is lost from rounding up the compressed page output (maybe 5KB) to the fixed page size (maybe 8KB).
- no page reads for secondary index maintenance - MyRocks does not read the old version of a secondary index entry during insert, update or delete maintenance for a non-unique secondary index. So this is a write-only operation compared to read-page, modify-page, write-page for a B-Tree. This greatly reduces the random IO overhead for some workloads (benchmark results to be shared soon).
- less IO capacity used for persisting changes - a B-Tree does more & smaller writes to persist a database while the MyRocks LSM does fewer & larger writes. Not only is less random IO capacity used, but the MyRocks LSM writes less data to storage per transaction compared to InnoDB as seen in the Linkbench results (look for wKB). In that case the difference was ~10X.
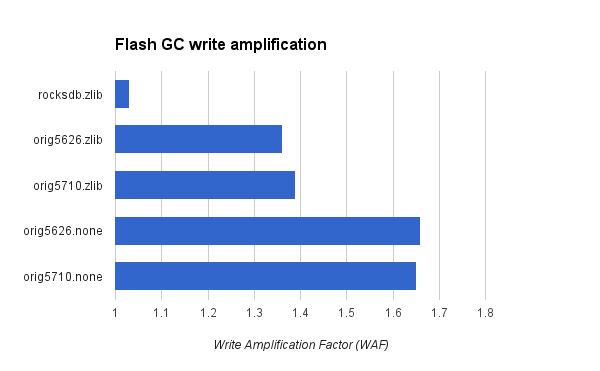
- less write amplification from flash GC - the write pattern from the MyRocks LSM is friendlier to flash GC compared to InnoDB. This leads to lower write-amplification so that InnoDB was writing up to 18X more data per transaction compared to MyRocks as seen in the Linkbench results.
- simpler code - RocksDB is much simpler than InnoDB. I have spent years with both -- debugging and reading code. MyRocks still has mutex contention, but the problem is easier to fix because the engine is simpler. New features are easier to add because the engine is simpler. We are moving fast to make MyRocks better.
The MyRocks Disadvantage
There is no free lunch with database algorithms. From theory
we can expect better efficiency on writes and worse efficiency from reads with an LSM compared to a B-Tree. But what does that mean in practice? This will take time to figure out and I try to include IO efficiency metrics in my benchmark results that include disk reads, disk KB read and disk KB written per transaction to understand the differences. But at this point the IO efficiency improvements I see from MyRocks are much greater than the IO efficiency losses.
MyRocks is not as feature complete as InnoDB. While the team is moving fast the MySQL storage engine API is hard and getting harder. Missing features include text, geo, native partitioning, online DDL and XA recovery on the master (keep binlog & RocksDB in sync on master). I am not sure that text & geo will ever get implemented. I hope to see XA recovery and partial support for online DDL this year.
MyRocks is not proven like InnoDB. This takes time, a variety of workloads and robust QA. It is getting done but I am not aware of anybody running MyRocks in production today.
An LSM might use more CPU per query because more data structures can be checked to satisfy a query. This can increase the number of CPU cache misses and key comparisons done per query. It is likely to be a bigger deal on CPU-bound workloads and my focus has been on IO-bound. One example of the difference is the tuning
that was required to make the MyRocks load performance match InnoDB when using fast storage. Although in that case the problem might be more of an implementation artifact than something fundamental to the LSM algorithm.
An LSM like MyRocks can also suffer from the range read penalty. An LSM might have to check many files to get data for a point or range query. Most LSMs, including MyRocks, use bloom filters to reduce the number of files to be checked during a point query. Bloom filters can eliminate all disk reads for queries of keys that don't exist. We have had some workloads on InnoDB for which 30% of the disk reads were for keys that don't exist.
Bloom filters can't be used on pure range queries. The most frequent query in Linkbench, and the real workload it models, is a short range query. Fortunately this query includes an equality predicate on the leading two columns of a covering secondary index (
see the id1_type index in the Linkbench schema) and RocksDB has a feature to create the bloom filter on a prefix of the key (innovation!).
Even when the prefix bloom filter can't be used the range read penalty can be overstated. It is important to distinguish between logical and physical reads. A logical read means that data is read from a file. A physical read means that a logical read had to use the storage device to get the data. Otherwise a logical read is satisfied from cache. A range query with an LSM can require more logical reads than a B-Tree. But the important question is whether it requires more physical reads.