I revisited prior work after taking more care to document the impact of the flags I use when compiling MyRocks. I ran two in-memory benchmarks (sysbench, insert benchmark) to understand the impact of the compile-time flags on CPU efficiency.
tl;dr:
- use CMAKE_BUILD_TYPE=Release
- enable link time optimization (-flto with gcc) via -DWITH_LTO=ON
- use -march=native & -mtune=native (if possible)
For MyRocks with FB MySQL 8.0.28 a build that uses both link time optimization and enables CPU specific optimizations (-march=native -mtune=native) (rel_native_lto) gets about 5% more throughput with the insert benchmark and 5%, 6%, 7% with sysbench for point queries, range queries and writes.
Disclaimer - the MySQL build for MyRocks wraps the RocksDB build and that gets in the way. While the RocksDB build respected most of the flags I used described below, I wasn't able to control usage of -march=native which ended up being used by RocksDB source files for all builds, even when I didn't want it to be used.
Compile time options
I tested the following builds for MyRocks. I wasn't able to get link time optimization working for the 5.6.35 builds. It might be possible but I stopped after trying for a few hours.
Note that in many cases with modern MySQL the use of CMAKE_BUILD_TYPE=RelWithDebInfo implies the use of link time optimization (-flto in gcc) while CMAKE_BUILD_TYPE=Release does not. With help from experts I documented that in this post. However, the only builds listed below that use link time optimization are ones with _lto in their name and that is done via -DWITH_LTO=ON.
I tested these builds for FB MySQL 5.6.35 at git sha 256826240. The CMake command lines are in the cmk.* files here:
I tested these builds for FB MySQL 5.6.35 at git sha 256826240. The CMake command lines are in the cmk.* files here:
- rel_withdbg - CMAKE_BUILD_TYPE=RelWithDebInfo which implies -O2
- rel_o2 - CMAKE_BUILD_TYPE=Release, explicitly set -O2
- rel - CMAKE_BUILD_TYPE=Release which implies -O3
I tested these builds for FB MySQL 8.0.28 at git sha 8fae2bbdc. The CMake command lines are in the cmk.* files here:
- rel_withdbg - CMAKE_BUILD_TYPE=RelWithDebInfo which implies -O2
- rel_o2 - CMAKE_BUILD_TYPE=Release, explicitly set -O2
- rel - CMAKE_BUILD_TYPE=Release which implies -O3
- rel_native - CMAKE_BUILD_TYPE=Release which implies -O3, added -march=native -mtune=native
- rel_o2_lto - CMAKE_BUILD_TYPE=Release, explicitly set -O2, added -flto
- rel_lto - CMAKE_BUILD_TYPE=Release which implies -O3, added -flto
- rel_native_lto - CMAKE_BUILD_TYPE=Release which implies -O3, added -march=native -mtune=native -flto
Benchmark HW
The HW is Beelink SER 4700u with 8 AMD cores, 16G RAM and fast NVMe SSD described here.
Benchmarks
The benchmarks were sysbench and the insert benchmark configured so that the database fits in memory. For some benchmark steps there were writes to storage but there were no reads from storage.
An overview of the insert benchmark is here and here. My scripts for running it are here. It was run in three configurations: 1 client & 1 table, 4 clients & 4 tables, 4 clients & 1 table and each run has 6 steps:
- l.i0 - insert 20M rows without secondary indexes
- l.x - create 3 secondary indexes
- l.i1 - insert 20M rows with 3 secondary indexes in place.
- q100 - range queries with 100 inserts/s in the background, runs for 30 minutes
- q500 - range queries with 500 inserts/s in the background, runs for 30 minutes
- q1000 - range queries with 1000 inserts/s in the background, runs for 1 hour
My scripts for running sysbench are here and the lua directory includes additional benchmark steps not included upstream. There are 42 Lua scripts for which I provide results. Each represents a (micro)benchmark step that was run for 10 minutes. I place them into three groups -- point, range, write -- based on the common operation done for each where point does point queries, range does range queries and write does insert/update/delete. This was repeated for two configurations: 1 table & 1 thread, 1 table & 4 threads.
Results: insert benchmark
The benchmark was repeated for three configurations. The links are to performance reports:
- 1 thread & 1 table: 5.6.35, 8.0.28, 5.6 vs 8.0
- 4 threads & 4 tables: 5.6.35, 8.0.28, 5.6 vs 8.0
- 4 threads & 1 table: 5.6.35, 8.0.28, 5.6 vs 8.0
A spreadsheet with the throughput for each benchmark step for each of the three configurations is here. Graphs with relative throughput for the 1 thread & 1 table configuration are below. By relative throughput I mean throughput for the build relative to the rel_withdbg build. The y-axis starts at 0.8 to improve readability. Graphs for the 4 thread configurations are similar. Conclusions from the graphs:
- For MyRocks with 5.6.35 the rel build usually has ~3% more throughput and with 8.0.28 the rel_native_lto build has ~5% more throughput compared to the base case (rel_withdbg).
- The l.x benchmark step has the most variance. I ignore that for now.
- Performance with the rel build (uses -O3) is slightly better than the rel_o2 builds (uses -O2)
- Using link time optimization helps (see results for rel_lto)
- Using -march=native -mtune=native helps (see results for rel_native_lto)
.png)

Results: sysbench
The benchmark was repeated for two configurations: 1 table & 1 thread, 1 table & 4 threads. In each case the table starts with 20M rows and each benchmark step ran for 10 minutes. The benchmark steps are grouped into three classes based on the dominant operation: point (for point queries), range (for range queries) and write (for insert, update & delete).
The best performance comes from the rel build in FB MySQL 5.6.35 and the rel_native_lto build in FB MySQL 8.0.28 as shown by the tables below with summary statistics. The numbers are the throughput for the build relative to the throughput for the rel_withdbg build and for all benchmark steps except scan the throughput is QPS while for scan it is millions rows read/second.
The spreadsheet with the throughput, summary statistics and graphs is here.
Summary statistics for MyRocks in FB MySQL 8.0.28 with the 1 table & 1 thread configuration show that the rel build on average gets 3% more QPS on point queries, 2% more on range queries and 0% more on writes relative to the rel_withdbg build. Results for the 1 table & 4 threads configuration are similar.
Summary statistics for MyRocks in FB MySQL 8.0.28 show that the rel_native_lto build provides the best performance and the rel_lto build is second best. The rel_native_build on average gets 5% more QPS on point queries, 7% more on range queries and 6% more on writes.
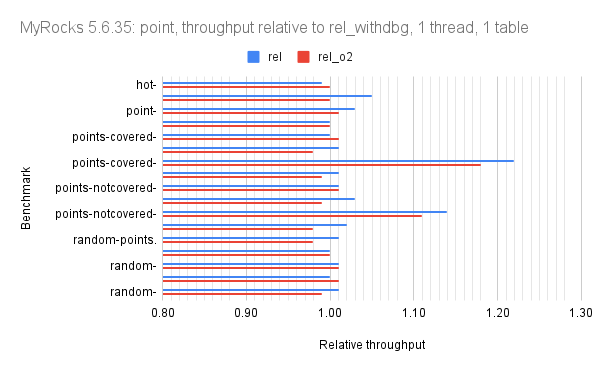
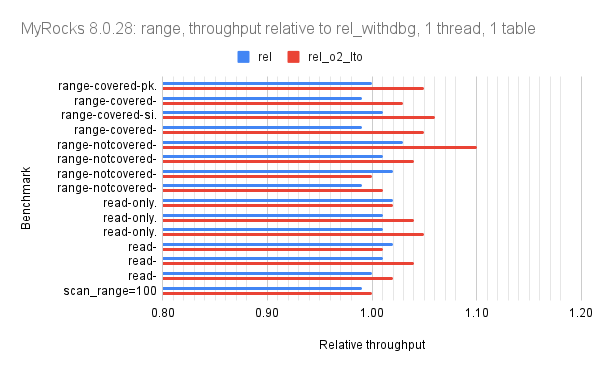
Results: sysbench graphs
There are a few outlier benchmark steps that get much more improvement than average in the rel build with 5.6.35 and the rel_native_lto_build with 8.0.22. They are visible in the graphs below. The x-axis for the graphs starts at 0.8 rather than 0 to improve readability.
For MyRocks in 5.6.35 the benchmark step names are:
- points-covered-si_range=100 - rel does 1.22X better
- points-notcovered-si_range=100 - rel does 1.14X better
- range-covered-si_range=100 - rel does 1.07X better
- read-write_range=100 - rel does 1.04X better
And for MyRocks in 8.0.28:
- hot-points_range=100 - rel_native_lto does 1.14X better
- point-query.pre_range=100 - rel_native_lto does 1.11X better
- point-query_range=100 - rel_native_lto does 1.11X better


Next the graphs for MyRocks in FB MySQL 8.0.28. These only have results for the rel_lto and rel_native_lto builds to improve readability.


No comments:
Post a Comment