- Database load is slightly faster
- Transaction processing is slightly slower
- DROP TABLE is 43X slower
MySQL 5.6 vs 5.7
I used a host with 24 HW threads, 144G of RAM and a 400G Intel s3700 SSD. The server uses Fedora 19, XFS and Linux kernel 3.14.27-100.fc19. The benchmark application is linkbench and was run with maxid1=100M, loaders=10 and requesters=20 (10 clients for the load, 20 for queries). I compared the Facebook patch for MySQL 5.6 with upstream MySQL 5.7. For 5.6 I used old-style compression for linktable and counttable. For 5.7 I used transparent compression for all tables. I also used 32 partitions for 5.6 and no partitions for 5.7. After the database was loaded I ran the query test for 140 loops with 1 hour per loop.
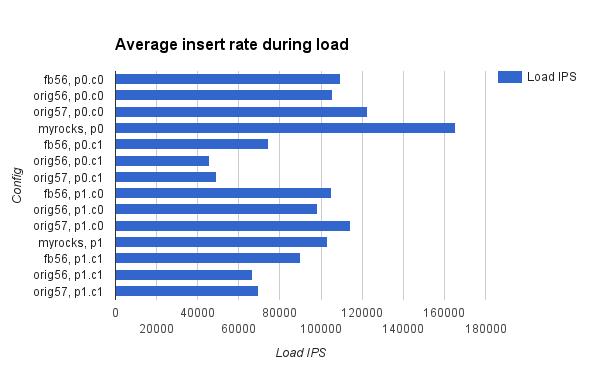
The table below has data for the Facebook patch for MySQL 5.6 (fb56) and upstream 5.7.8 (orig578). The results are the row insert rate during the load (ips) and the average QPS of the Nth hourly run (qps@N). The QPS is better for MySQL 5.6 and the load rate is better for 5.7 but I don't know how much of that is due to the use of partitions for 5.6. I ran DROP TABLE after the test and that took ~8 minutes for MySQL 5.7.8. More details are in a previous post.
fb56 orig578
ips 55199 81970
qps@20 13731 10581
qps@40 12172 9874
qps@60 11353 8875
qps@80 10977 8234
qps@100 10793 8021
qps@120 10691 7946
qps@140 10636 7949
Transparent vs old-style compression
I then ran a test for 24 hours to compare MySQL 5.7.8 in two setups and both used partitions for all tables. They differed in that one used old-style compression and the other used transparent compression. The results were similar to the comparison with MySQL 5.6 as the load was faster with transparent compression. transaction processing was faster with old-style compression and DROP TABLE was ~30X slower with transparent compression.
After the linkbench load I ran the query test for 24 1-hour loops. At test end the database with old-style compression was 4% larger than transparent compression, but it also had more data as it sustained a higher QPS rate. I didn't count the number of rows to determine whether it had 4% more data.
The table below displays the row insert rate during the load (ips) and the average QPS from 1-hour runs at the 2nd, 12th and 24th hours (qps@N). The load rate is better with transparent compression and the QPS is better with old-style compression.
After the linkbench load I ran the query test for 24 1-hour loops. At test end the database with old-style compression was 4% larger than transparent compression, but it also had more data as it sustained a higher QPS rate. I didn't count the number of rows to determine whether it had 4% more data.
The table below displays the row insert rate during the load (ips) and the average QPS from 1-hour runs at the 2nd, 12th and 24th hours (qps@N). The load rate is better with transparent compression and the QPS is better with old-style compression.
578, old-style 578, transparent
ips 72566 79518
qps@2 16542 15504
qps@12 16079 15136
qps@24 15506 14383
Transparent compression doesn't have to provide better compression or performance to be a win, but it needs to be stable. I ran DROP DATABASE at test end and that took 5 seconds for old-style compression vs 216 seconds for transparent. The database was ~100G when dropped.
This paste has the output from the 24th 1-hour run of the linkbench query test. There are two sections, the first is from old-style compression and the second from transparent compression. For most of the linkbench operations old-style is slightly faster. But the max times for operations is much worse (~2X) with transparent.