- InnoDB writes between 8X and 14X more data to SSD per transaction than RocksDB
- RocksDB sustains about 1.5X more QPS
- Compressed/uncompressed InnoDB uses 2X/3X more SSD space than RocksDB
Configuration
I used the same configuration as described in the previous post with one difference. For this test I ran 168 iterations of the query step and each step ran for 1 hour. The test ran for 7 days while the previous test ran for 1 day. What I describe as QPS below is TPS (transactions/second) and when I use per query below I mean per transaction. The IO efficiency metrics are measured by iostat. I report the database size in GB at the end of each day - hours 1, 24, 48, 72, 96, 120, 144 and 168. For each one hour interval I collect:
- average QPS
- iostat reads per query (r/q)
- iostat KB read per query(rKB/q)
- iostat KB written per query (wKB/q)
- iostat reads per second (r/s)
- iostat KB read per second (rKB/s)
- iostat KB written per second (wKB/s)
- myrocks.zlib - Facebook MySQL 5.6, RocksDB with zlib compression
- innodb56.none - upstream MySQL 5.6.26, InnoDB without compression
- innodb57.none - upstream MySQL 5.7.10, InnoDB without compression
- innodb56.zlib - upstream MySQL 5.6.26, InnoDB with zlib compression
- innodb57.zlib - upstream MySQL 5.7.10, InnoDB with zlib compression
Better Compression
Compressed InnoDB uses about 2X more SSD space than MyRocks. Uncompressed InnoDB uses about 3.1X more SSD space than MyRocks. This graph shows the database size every 24 hours. Note that the database gets more data as a function of the QPS rate and MyRocks has more data than InnoDB after 168 hours -- myrocks.zlib has 6.4% more rows than inno57.none and 7.2% more rows than inno57.zlib after 7 days.

Better Performance
I'd be happy if MyRocks matched the QPS from InnoDB and only beat it on IO efficiency. But it wins on QPS and IO efficiency. The data below is QPS over time. MyRocks gets at least 1.5X more QPS than compressed InnoDB. It also does a lot better than uncompressed InnoDB but who wants to use 3X more SSD space. The QPS growth at test start for InnoDB with zlib happens because there are stalls until the compressed b-tree pages fragment. I think this is a problem with mutexes in the pessimistic insert/update code for compressed InnoDB.
The graph below shows the average QPS from each 1-hour interval.

Better IO Efficiency
I present IO efficiency metrics here using data from iostat normalized by the QPS rate to show the amount of IO done per transaction.
This result is remarkable. InnoDB writes between 8X and 14X more to storage per transaction than MyRocks. This means that workloads can use TLC SSD with MyRocks when InnoDB requires MLC and that workloads can use SSD with MyRocks when SSD doesn't have sufficient endurance for InnoDB. Running a busy database on SSD is so much easier than using disk.
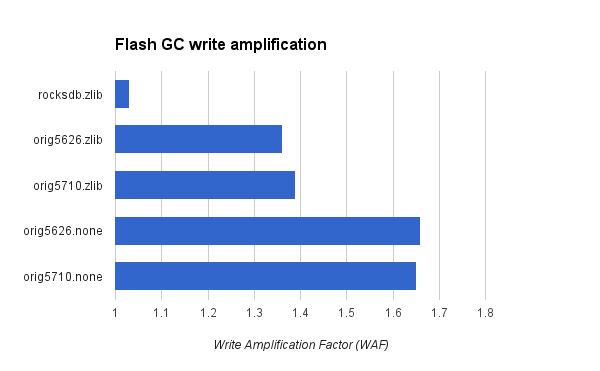
This result doesn't include the additional write-amplification from flash GC that occurs with InnoDB compared to MyRocks because the MyRocks write pattern generates less work for flash GC. I previously described how that increased the flash write-rate by about 1.5X for InnoDB compared to RocksDB for the device I use. This means that the real difference in write rates on SSD might mean that InnoDB writes 12X to 21X more to storage than MyRocks.
Using iostat metrics from hour 168 InnoDB writes 8.7, 10.5, 8.9 and 10.6 times more to storage per transaction compared to RocksDB. Using iostat data from hour 167 the difference is 11.5, 13.9, 11.7 and 14.0 times more data written.
The graph below shows the number of KB written to SSD per transaction from each 1-hour interval.

This graph shows the number of SSD reads per transaction. MyRocks has the smallest rate. While an LSM can have an IO penalty for range queries and range queries are the most frequent operation in Linkbench, that isn't a problem for this workload.

This graph shows the number of KB read from SSD per transaction. The rate for MyRocks is in between the rates for compressed and uncompressed InnoDB. The r/q rate is more important than this rate as long as the difference here isn't extreme. The rate for MyRocks includes reads done for user queries and reads done in the background for compaction.

Absolute iostat results
These graphs show absolute rates from iostat. The data is the average rate per 1-hour interval.
The first graph is the rate for iostat r/s. The rate is larger for MyRocks because it sustains the most QPS.

The next graph shows the rate for iostat wKB/s. Note that InnoDB sustains between 100 and 200 MB/s of writes. The SSD device is much busier doing writes for InnoDB than for MyRocks. IO capacity used for writes isn't available for reads even when endurance isn't an issue. More writes means more erases from flash GC and erases are a source of IO stalls when a read gets stuck behind the erase on the same channel.

The last graph shows the rate for iostat rKB/s. The rates are larger for uncompressed InnoDB and MyRocks compared to uncompressed InnoDB. The SSD is very busy if you combine the iostat rates for rKB/s and wKB/s.