This has results for the Insert Benchmark using MyRocks 5.6 and 8.0 using a large server and cached workload.
tl;dr
- performance between MyRocks 5.6.35, 8.0.28 and 8.0.32 are similar, unlike what I see with InnoDB where there are large changes, both good (writes) and bad (for reads) using the same setup
I tested MyRocks 5.6.35, 8.0.28 and 8.0.32. These were compiled from source. All builds use CMAKE_BUILD_TYPE =Release.
- MyRocks 5.6.35
- compiled with clang on Dec 21, 2023 at git hash 4f3a57a1, RocksDB 8.7.0 at git hash 29005f0b
- MyRocks 8.0.28
- compiled with clang on Dec 22, 2023 at git hash 2ad105fc, RocksDB 8.7.0 at git hash 29005f0b
- MyRocks 8.0.32
- compiled with clang on Dec 22, 2023 at git hash 76707b44, RocksDB 8.7.0 at git hash 29005f0b
Benchmark
The benchmark is run with 24 clients to avoid over-subscribing the CPU. The server has 40 cores, 80 HW threads (hyperthreads enabled), 256G of RAM and many TB of fast SSD.
I used the updated Insert Benchmark so there are more benchmark steps described below. In order, the benchmark steps are:
- l.i0
- insert 20 million rows per table in PK order. The table has a PK index but no secondary indexes. There is one connection per client.
- l.x
- create 3 secondary indexes per table. There is one connection per client.
- l.i1
- use 2 connections/client. One inserts 50M rows and the other does deletes at the same rate as the inserts. Each transaction modifies 50 rows (big transactions). This step is run for a fixed number of inserts, so the run time varies depending on the insert rate.
- l.i2
- like l.i1 but each transaction modifies 5 rows (small transactions).
- qr100
- use 3 connections/client. One does range queries for 3600 seconds and performance is reported for this. The second does does 100 inserts/s and the third does 100 deletes/s. The second and third are less busy than the first. The range queries use covering secondary indexes. This step is run for a fixed amount of time. If the target insert rate is not sustained then that is considered to be an SLA failure. If the target insert rate is sustained then the step does the same number of inserts for all systems tested.
- qp100
- lik qr100 except uses point queries on the PK index
- qr500
- like qr100 but the insert and delete rates are increased from 100/s to 500/s
- qp500
- like qp100 but the insert and delete rates are increased from 100/s to 500/s
- qr1000
- like qr100 but the insert and delete rates are increased from 100/s to 1000/s
- qp1000
- like qp100 but the insert and delete rates are increased from 100/s to 1000/s
Results
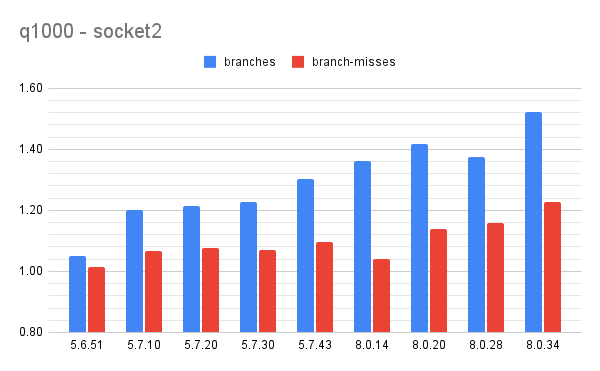
The performance report is here. It has a lot more detail including charts, tables and metrics from iostat and vmstat to help explain the performance differences.
From the summary throughput is similar between MyRocks 5.6 and 8.0. The summary has 3 tables. The first shows absolute throughput by DBMS tested X benchmark step. The second has throughput relative to MyRocks 5.6.35. The third shows the background insert rate for benchmark steps with background inserts and all systems sustained the target rates. The second table makes it easy to see how performance changes over time.
Another report is here and the difference is that I changed the benchmark to wait for X seconds after l.i2 to reduce writeback debt before the read-write steps start. And X is max(1200, 60 + #rows/1M). The goal is to reduce variance for the read-write benchmark steps.
Another report is here and the difference is that I changed the benchmark to wait for X seconds after l.i2 to reduce writeback debt before the read-write steps start. And X is max(1200, 60 + #rows/1M). The goal is to reduce variance for the read-write benchmark steps.
From the HW efficiency metrics per benchmark step
- l.i0, l.x
- metrics are similar
- l.i1
- most metrics are similar but CPU overhead (cpupq) is ~13% larger in 8.0 and max response time (max_op) is more than 2X larger in 8.0
- l.i2
- most metrics are similar but CPU overhead (cpupq) is ~39% larger in 8.0 and max response time (max_op) is more than 2X larger in 8.0
- qr100, qp100, qr500, qp500, qr1000, qp1000
- metrics are similar
It is interesting that the CPU overhead is larger for MyRocks 8.0.28 and 8.0.32 during the l.i1 and l.i2 benchmark steps because throughput and response time distributions are similar to MyRocks 5.6.35. So the extra CPU in MyRocks 8.0 does not appear to occur in the foreground threads that processes the insert and delete statements.
The CPU overhead from compaction is 3% to 6% larger for MyRocks 8.0 -- see the CompMergeCPU(sec) column on the Sum line for 5.6.35, 8.0.28 and 8.0.32. But that can only explain a few (<= 5) usecs/operation of CPU overhead -- not the 20 to 100+ that I want to explain.
If I just look at the output from ps aux | grep mysqld I see that MyRocks 8.0 uses at least 1.2X more CPU than 5.6. But again, that can be from background activities and might not be on the path for foreground operations (queries).
For now this is a mystery to which I will return later.








.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)






.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)